Scaling out
Description
This example architecture is designed to provide scalability. It includes three nodes: two combined ClickHouse plus coordination (ClickHouse Keeper) servers, and a third server with only ClickHouse Keeper to finish the quorum of three. With this example, we'll create a database, table, and a distributed table that will be able to query the data on both of the nodes.
Level: Basic
Terminology
Replica
A copy of data. ClickHouse always has at least one copy of your data, and so the minimum number of replicas is one. This is an important detail, you may not be used to counting the original copy of your data as a replica, but that is the term used in ClickHouse code and documentation. Adding a second replica of your data provides fault tolerance.
Shard
A subset of data. ClickHouse always has at least one shard for your data, so if you do not split the data across multiple servers, your data will be stored in one shard. Sharding data across multiple servers can be used to divide the load if you exceed the capacity of a single server. The destination server is determined by the sharding key, and is defined when you create the distributed table. The sharding key can be random or as an output of a hash function. The deployment examples involving sharding will use rand() as the sharding key, and will provide further information on when and how to choose a different sharding key.
Distributed coordination
ClickHouse Keeper provides the coordination system for data replication and distributed DDL queries execution. ClickHouse Keeper is compatible with Apache ZooKeeper.
Environment
Architecture Diagram
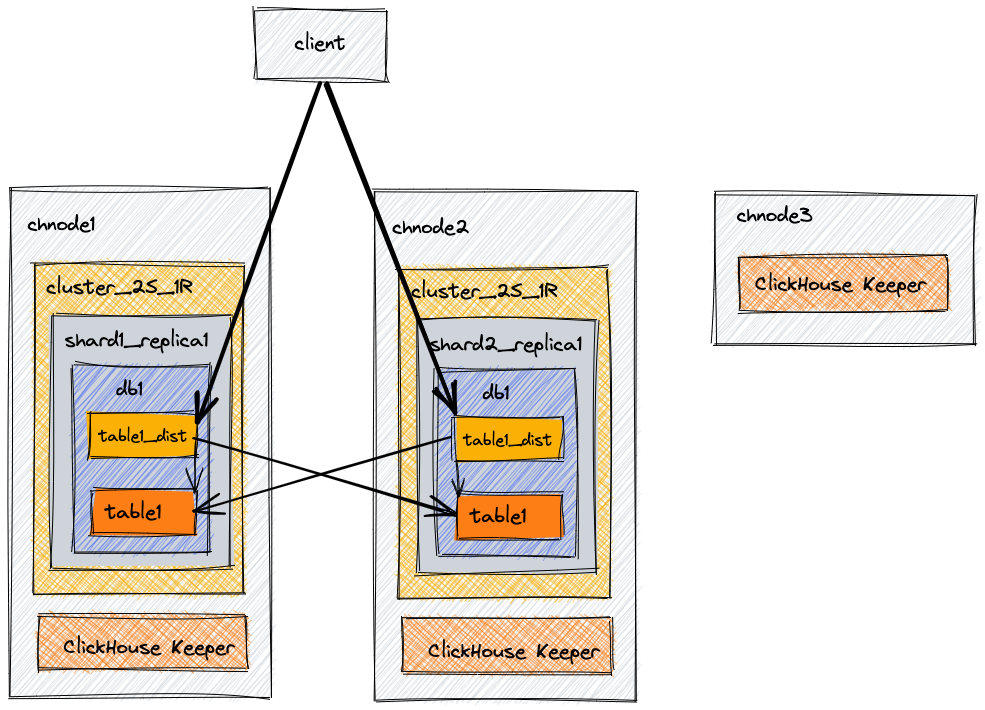
| Node | Description |
|---|---|
| chnode1 | Data + ClickHouse Keeper |
| chnode2 | Data + ClickHouse Keeper |
| chnode3 | Used for ClickHouse Keeper quorum |
In production environments we strongly recommend that ClickHouse Keeper runs on dedicated hosts. This basic configuration runs the Keeper functionality within the ClickHouse Server process. The instructions for deploying ClickHouse Keeper standalone are available in the installation documentation.
Install
Install Clickhouse on three servers following the instructions for your archive type (.deb, .rpm, .tar.gz, etc.). For this example, you will follow the installation instructions for ClickHouse Server and Client on all three machines.
Editing configuration files
When configuring ClickHouse Server by adding or editing configuration files you should:
- Add files to
/etc/clickhouse-server/config.d/directory - Add files to
/etc/clickhouse-server/users.d/directory - Leave the
/etc/clickhouse-server/config.xmlfile as it is - Leave the
/etc/clickhouse-server/users.xmlfile as it is
chnode1 configuration
For chnode1, there are five configuration files. You may choose to combine these files into a single file, but for clarity in the documentation it may be simpler to look at them separately. As you read through the configuration files, you will see that most of the configuration is the same between chnode1 and chnode2; the differences will be highlighted.
Network and logging configuration
These values can be customized as you wish. This example configuration gives you a debug log that will roll over at 1000M three times. ClickHouse will listen on the IPv4 network on ports 8123 and 9000, and will use port 9009 for interserver communication.
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper configuration
ClickHouse Keeper provides the coordination system for data replication and distributed DDL queries execution. ClickHouse Keeper is compatible with Apache ZooKeeper. This configuration enables ClickHouse Keeper on port 9181. The highlighted line specifies that this instance of Keeper has server_id of 1. This is the only difference in the enable-keeper.xml file across the three servers. chnode2 will have server_id set to 2, and chnode3 will have server_id set to 3. The raft configuration section is the same on all three servers, and it is highlighted below to show you the relationship between server_id and the server instance within the raft configuration.
If for any reason a Keeper node is replaced or rebuilt, do not reuse an existing server_id. For example, if the Keeper node with server_id of 2 is rebuilt, give it server_id of 4 or higher.
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>1</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
Macros configuration
The macros shard and replica reduce the complexity of distributed DDL. The values configured are automatically substituted in your DDL queries, which simplifies your DDL. The macros for this configuration specify the shard and replica number for each node.
In this 2 shard 1 replica example, the replica macro is replica_1 on both chnode1 and chnode2 as there is only one replica. The shard macro is 1 on chnode1 and 2 on chnode2.
<clickhouse>
<macros>
<shard>1</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
Replication and sharding configuration
Starting from the top:
- The
remote_serverssection of the XML specifies each of the clusters in the environment. The attributereplace=truereplaces the sampleremote_serversin the default ClickHouse configuration with theremote_serversconfiguration specified in this file. Without this attribute, the remote servers in this file would be appended to the list of samples in the default. - In this example, there is one cluster named
cluster_2S_1R. - A secret is created for the cluster named
cluster_2S_1Rwith the valuemysecretphrase. The secret is shared across all of the remote servers in the environment to ensure that the correct servers are joined together. - The cluster
cluster_2S_1Rhas two shards, and each of those shards has one replica. Take a look at the architecture diagram toward the beginning of this document, and compare it with the twosharddefinitions in the XML below. In each of the shard definitions there is one replica. The replica is for that specific shard. The host and port for that replica is specified. The replica for the first shard in the configuration is stored onchnode1, and the replica for the second shard in the configuration is stored onchnode2. - Internal replication for the shards is set to true. Each shard can have the
internal_replicationparameter defined in the config file. If this parameter is set to true, the write operation selects the first healthy replica and writes data to it.
<clickhouse>
<remote_servers replace="true">
<cluster_2S_1R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_2S_1R>
</remote_servers>
</clickhouse>
Configuring the use of Keeper
Up above a few files ClickHouse Keeper was configured. This configuration file use-keeper.xml is configuring ClickHouse Server to use ClickHouse Keeper for the coordination of replication and distributed DDL. This file specifies that ClickHouse Server should use Keeper on nodes chnode1 - 3 on port 9181, and the file is the same on chnode1 and chnode2.
<clickhouse>
<zookeeper>
<node index="1">
<host>chnode1</host>
<port>9181</port>
</node>
<node index="2">
<host>chnode2</host>
<port>9181</port>
</node>
<node index="3">
<host>chnode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
chnode2 configuration
As the configuration is very similar on chnode1 and chnode2, only the differences will be pointed out here.
Network and logging configuration
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper configuration
This file contains one of the two differences between chnode1 and chnode2. In the Keeper configuration the server_id is set to 2.
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>2</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
Macros configuration
The macros configuration has one of the differences between chnode1 and chnode2. shard is set to 2 on this node.
<clickhouse>
<macros>
<shard>2</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
Replication and sharding configuration
<clickhouse>
<remote_servers replace="true">
<cluster_2S_1R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_2S_1R>
</remote_servers>
</clickhouse>
Configuring the use of Keeper
<clickhouse>
<zookeeper>
<node index="1">
<host>chnode1</host>
<port>9181</port>
</node>
<node index="2">
<host>chnode2</host>
<port>9181</port>
</node>
<node index="3">
<host>chnode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
chnode3 configuration
As chnode3 is not storing data and is only used for ClickHouse Keeper to provide the third node in the quorum, chnode3 has only two configuration files, one to configure the network and logging, and one to configure ClickHouse Keeper.
Network and logging configuration
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper configuration
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
Testing
- Connect to
chnode1and verify that the clustercluster_2S_1Rconfigured above exists
SHOW CLUSTERS
┌─cluster───────┐
│ cluster_2S_1R │
└───────────────┘
- Create a database on the cluster
CREATE DATABASE db1 ON CLUSTER cluster_2S_1R
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode2 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode1 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- Create a table with MergeTree table engine on the cluster.Note
We do not need not to specify parameters on the table engine since these will be automatically defined based on our macros
CREATE TABLE db1.table1 ON CLUSTER cluster_2S_1R
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode1 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode2 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- Connect to
chnode1and insert a row
INSERT INTO db1.table1 (id, column1) VALUES (1, 'abc');
- Connect to
chnode2and insert a row
INSERT INTO db1.table1 (id, column1) VALUES (2, 'def');
- Connect to either node,
chnode1orchnode2and you will see only the row that was inserted into that table on that node. for example, onchnode2
SELECT * FROM db1.table1;
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
- Create a distributed table to query both shards on both nodes.
(In this exmple, the
rand()function is set as the sharding key so that it randomly distributes each insert)
CREATE TABLE db1.table1_dist ON CLUSTER cluster_2S_1R
(
`id` UInt64,
`column1` String
)
ENGINE = Distributed('cluster_2S_1R', 'db1', 'table1', rand())
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode2 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode1 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- Connect to either
chnode1orchnode2and query the distributed table to see both rows.
SELECT * FROM db1.table1_dist;
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘